云上使用 Redis?十件事必知!
本文翻译自 Using Redis on Cloud? Here are ten things you should know。
我们很难操作大规模的有状态的分布式系统,Redis 也一样不能例外。托管数据库承担了许多繁重的工作,让我们生活更加轻松。但你仍然需要一个良好的架构,并在服务器(Redis)和客户端(应用程序)上应用最佳实践。
本文涵盖了一系列与 Redis 相关的最佳实践、技巧和窍门,包括集群可伸缩性、客户端配置、集成、指标等。虽然我会不时引用 Amazon MemoryDB 和用于 Redis 的 ElastiCache ,但大多数情况(即使不是全部)都适用于 Redis 集群。
无论如何,这并不是一份详尽的清单。我只是随意选择了 10,因为十全十美!
让我们从扩展 Redis 集群的选项开始吧。
1.可伸缩性选
你可以缩或者放:
- 向上扩展(纵向)——你可以增加单个节点/实例的容量,例如将 Amazon EC2 从
db.r6g.xlarge类型升级为db.r6g.2xlarg。 - 向外扩展(横向)——可以向集群添加更多节点
横向扩展的需求可能由以下几个原因驱动。
如果需要处理读取繁重的工作负载,可以选择添加更多副本节点。这适用于 Redis 集群设置(如 MemoryDB)或非集群主副模式,如禁用集群模式的 ElastiCache。
如果你想增加写容量,你会发现自己受到主副模式的限制,应该选择基于 Redis 集群的设置。你可以增加集群中的分片数量,这是因为只有主节点可以接受写入,而每个分片只能有一个主节点。
还具有提高总体高可用性的额外好处。
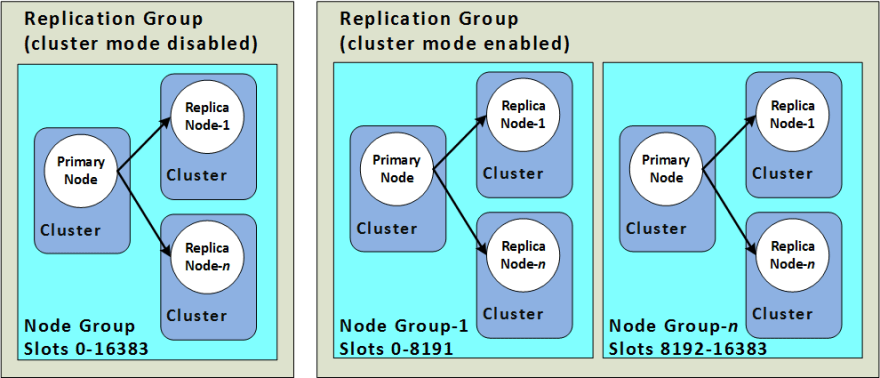
2.扩展群集后,你最好使用这些副本!
大多数 Redis Cluster 客户端(包括 redis-cli)的默认行为是将所有读取重定向到主节点。如果你已经添加了读取副本以扩展读取流量,那么这些副本将处于空闲状态!
你需要切换到 READONLY 模式,以确保副本处理所有读取请求而不仅仅是被动参与者。确保正确配置 Redis 客户端——这会因客户端和编程语言而异。
例如,在 Go Redis 客户端中,你可以将 ReadOnly 设置为 true:
client := redis.NewClusterClient(
&redis.ClusterOptions{
Addrs: []string{clusterEndpoint},
ReadOnly: true,
//..other options
})
要进一步优化,你还可以使用 RouteByLatency 或 RouteRandomly,两者都会自动打开 ReadOnly 模式。
你可以参考 Java ��客户端,如 Lettuce 的工作原理。
3.使用读副本时注意一致性特征
你的应用程序可能会从副本中读取过时的数据,这就是实际的最终一致性。由于主节点到副本节点的复制是异步的,因此你发送到主节点的写入可能尚未反映在读副本中。当你有大量读副本(特别是跨多个可用性区域的读副本)时,可能会出现这种情况。如果这对于你的使用情况来说是不可接受的,那么你也必须使用主节点进行读取。
MemoryDB 或用于 Redis 的 ElastiCache 中的 ReplicationLag 指标 可用于检查副本应用主节点更改的时间差(以秒为单位)。
强一致性呢?
对于 MemoryDB,来自主节点的读取是强一致的。这是因为客户端应用程序只有在写入(主节点)到持久的 Multi-AZ 事务日志后才会收到成功的写入确认。
4.记住,你可以影响密钥在 Redis 集群中的分布方式
Redis 没有使用�一致哈希(与许多其他分布式数据库一样),而是使用哈希槽的概念。总共有 16384 个插槽,一系列哈希插槽分配给集群中的每个主节点,每个密钥属于一个特定的哈希槽(因此分配给一个特定节点)。如果密钥属于不同的哈希槽,则在 Redis 集群上执行的多密钥操作无法工作。
但是,你并不是完全听任集群的摆布!可以通过使用哈希标记来影响键的位置。因此,可以确保特定键具有相同的哈希槽。例如,如果你将客户 ID 42 的订单存储在名为 customer:42:orders 的 HASH 中,而客户概要信息存储在 customer:42:profile 中,则可以使用大括号 {} 定义将被散列的特定子字符串。在本例中,我们的键是 {customer:42}:orders 和 {customers:42}:profile-{customer:42},驱动了散列槽的位置。现在我们可以确信,这两个密钥将位于相同哈希槽中(因此是同一个节点)。
5.你考虑过收缩比例吗?
你的应用程序很成功,它有很多用户和流量。你缩小了集群,事情仍然进展顺利。令人惊叹的
但如果你需要缩减规模呢?
在这样做之前,你需要注意以下几点:
- 每个节点上是否有足够的可用内存?
- 这可以在非高峰时间完成吗?
- 它将如何影响你的客户端应用程序?
- 在此阶段,你可以监控哪些指标?(例如
CPUUtilization、CurrConnections等)
参阅一些用于 Redis 的 MemoryDb 文档中的最佳实践,以更好地规划扩展。
6.当出错时……
让我们面对现实吧,失败是令人羡慕的。重要的是你是否准备好了?对于你的 Redis 集群,需要考虑以下几点:
- **你是否测试了应用程序/服务在出现故障时的行为?**如果没有,请这样做!使用 MemoryDB 和用于 Redis 的 ElastiCache,你可以利用故障转移 API 模拟主节点故障并触发故障转移。
- **你有副本节点吗?**如果你只有一个分片和一个主节点,那么如果该节点出现故障,你肯定会停机。
- **你有多个分片吗?**如果您只有一个分片(包含主分片和副本碎片),那么在该碎片的主节点发生故障的情况下,集群将无法接受任何写入。
- **你的分片是否跨越多个可用性区域?**如果你有跨多个 AZ 的分片,你要更好地准备处理 AZ 故障。
在所有情况下,MemoryDB 都可以确保在节点更换或故障切换期间不会丢失数据。
7.连不上 Redis,求助!
可能是网络/安全配置
这件事总是让人们感到困惑!你的 位于 VPC 中的 Redis 节点,可使用 MemoryDB 和 ElastiCache。如果你将客户端应用程序部署到 AWS Lambda、EKS、ECS、App Runner等计算服务,则需要确保你有正确的配置,特别是 VPC 和安全组。
这可能因你使用的计算平台而异。例如,与 App Runner(通过 VPC 连接器)甚至 EKS(虽然概念上是相同的)相比,通过访问 VPC 中的资源的方式配置 Lambda 函数略有不同。
8.Redis 6 带有访问控制列表——用它!
没有理由不对 Redis 集群应用身份验证(用户名/密码)和授权(基于 ACL 的权限)。MemoryDB 兼容 Redis 6 并支持 ACL。然而,为了符合较旧的 Redis 版本,它为每个帐户配置一个默认用户(用户名 default)和一个不可变的 ACL,称为 open-access。如果创建 MemoryDB 集群并将其与此 ACL 关联:
- 客户端无需身份验证即可连接
- 客户端可以对任何密钥执行任何命令(也没有权限或授权)
作为最佳实践:
- 定义明确的 ACL
- 添加用户(以及密码),以及
- 根据您的安全要求配置访问字符串。
你应该监视身份验证失败。例如,MemoryDB 中的 AuthenticationFailures指标为你提供了失败的身份验证尝试的总数——为此设置警报以检测未经授权的访问尝试。
别忘了周边安全
如果你已经在服务器上配置了 TLS,请不要忘记在客户端中也使用它!例如,使用 Go Redis:
client := redis.NewClusterClient(
&redis.ClusterOptions{
Addrs: []string{clusterEndpoint},
TLSConfig: &tls.Config{MaxVersion: tls.VersionTLS12},
//..other options
})
不使用它会导致你的错误不够明显(例如,常见的 i/o timeout),并使调试变得困难——这是你需要小心的事情。
9.有些事你不能做
作为托管数据库服务,MemoryDB 或 ElastiCache 限制了对某些 Redis 命令的访问。例如,你不能使用与 CLUSTER 相关的命令的子集,因为集群管理(伸缩、切分等)是由服务本身完成的。
但是,在某些情况下,你可能会找到其他选择。可以将监视运行缓慢的查询作为一个示例。尽管不能使用 CONFIG SET 配置 latency-monitor-threshold,但可以在参数组设置 slowlog-log-slower-than,然后使用 slowlog get 进行比较。
10.使用连接池
你的 Redis 服务器节点(即使是功能强大的节点)拥有有限的资源。其中之一是支持一定数量的并发连接的能力。大多数 Redis 客户端都提供连接池,作为有效管理到 Redis 服务器的连接的一种方式。重复使用连接不仅有利于你的 Redis 服务器,而且由于开销较小,客户端性能也得到了改善——这在高容量情况下至关重要。
ElastiCache 提供了可以跟踪的一些指标:
CurrConnections:客户端连接数(不包括来自读取副本的连接)NewConnections:服务器在特定时间段内接受的连接总数。
11.(附加)使用合适的连接模式
这是一个很明显的问题,但我还是要把它说出来,因为这是我亲眼目睹的人们犯的最常见的“开始”错误之一。
你在客户端应用程序中使用的连接模式将取决于你是否使用独立的 Redis 设置,即 Redis 集群(很可能)。大多数 Redis 客户端都明确区分了它们。例如,如果你使用启用了 MemoryDB 或 Elasticache 集群模式的 Go Redis 客户端,则需要使用 NewClusterClient(而不是 NewClient):
redis.NewClusterClient(&redis.ClusterOptions{//....})
有趣的是,有一个 UniversalClient 选项更灵活(写作期间,此为 Go Redis v9)。
如果没有使用正确的连接模式,你会得到一个报误。但有时,根本原因会隐藏在常见的错误消息之后——所以你需要保持警惕。
总结
你所做的架构选择最终将由你的特定需求驱动。我鼓励你浏览以下博文,深入了解 MemoryDB 和用于 Redis 的 ElastiCache 的性能特征,以及它们可能如何影�响解决方案的设计方式:
- 优化 Amazon ElastiCache 和 MemoryDB 的 Redis 客户端性能
- 最佳实践:Redis 客户端和用于 Redis 的 Amazon ElastiCache
- 测量用于 Redis 的 Amazon MemoryDB 的数据库性能
欢迎分享你的 Redis 窍门、技巧和建议。直到永远,快乐构建!