白话架构(4)——从瀑布到螺旋:60年软件研发模型进化史,藏着每个程序员的工作密码
巴利·玻姆:软件工程的本质,是在不确定性中寻找确定性的艺术。
作为软件工程师的我们,有没有在那一刹那,思考过这个问题:为什么有的项目能按时上线零bug,有的却卡在需求变更里反复返工?
答案,藏在软件研发模型的进化史里。
上一篇我们聊了软件行业的造神者,今天这篇聚焦和瀑布模型强相关的研发模型——从被误读的瀑布模型,到能应对高风险项目的螺旋模型,再到至今仍在悄悄用的RAD模型,每一种模型的诞生,都是程序员和项目失控的博弈史。
开篇暴击:被全行业误读的瀑布模型,诞生初衷竟是“预警缺陷”
1970年,温斯顿·罗伊斯(Winston Royce)在论文里写下了瀑布模型的核心框架,但他万万没想到:自己写这篇论文的目的,是警告大家这个模型的缺陷(比如线性流程扛不住需求变更),结果却被全行业当成了“研发圣经”。

图:温斯顿·罗伊斯
为啥会被误读?核心是时代刚需:当时的软件项目需求��简单,行业急需一套标准化流程规范混乱的开发行为。于是,这个本是“负面案例”的模型被推上神坛,瀑布模型(Waterfall Model)的名字正式敲定——而类似的线性开发实践,其实早已在行业里悄悄用了十几年。
瀑布模型的核心逻辑特别好懂:像瀑布一样单向倾泻,每个阶段彻底完成后才进入下一个,环环相扣不回头。核心阶段就6个:需求分析,设计,开发,测试,部署,维护。完美适配“需求100%明确、几乎不变更”的大型工程。
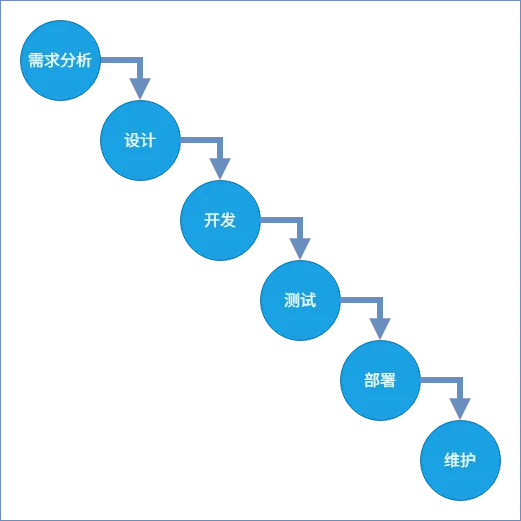
图:瀑布模型
但说出来你可能不信,它的雏形早在第一代计算机时代就有了。
溯源:比1970年早14年,世界首个大型计算机网络就用了“类瀑布流程”
瀑布模型不是突然冒出来的,而是从大型项目实践里“长”出来的。
1950年代初到1963年,美国空军搞了个大项目——SAGE半自动地面防空系统,这是世界上第一个大型实时计算机网络。为了保证这个“国之重器”不出错,团队用了一套“先明确需求、再设计、后开发测试”的线性流程,这就是最早的“类瀑布实践”。

图:防空导弹示意图
这里还有个有趣的小插曲:SAGE系统的核心——AN/FSQ-7计算机,是由 IBM 全权负责开发、构建和维护的。
作为20世纪50年代全球最大的计算机项目,SAGE 堪称 IBM 的“成长加速器”:1952年到1955年期间,这个项目为 IBM 贡献了80%的计算机业务收入;到1958年,参与该项目的 IBM 员工更是超过7000人。更关键的是,SAGE项目催生了大量技术创新,而 IBM 后续将这些创新成果广泛融入到其他计算机产品中,进一步巩固了自身在行业内的地位。
更关键的是,1956年6月29日,赫伯特·D·贝内特(Herbert D. Benington)在“数字计算机高级编程方法研讨会”上,专门以 SAGE 系统为例,写了篇《Production of Large Computer Programs》,第一次系统讲了大型软件的阶段化生产流程——这是目前有文献记载的、最早的类瀑布实践,比罗伊斯1970年的论文早了14年。

图:《Production of Large Computer Programs》 截图
后来,这套流程成了“大型关键项目标配”:IBM 704/709大型机的配套软件、NASA水星计划和双子座计划的载人航天软件、UNIVAC 系列商用软件,全用了瀑布模型。
这些项目有个共性:需求由军方或政府拍板,几乎不可能变;团队动辄几百上千人;交付的是不能出半点错的关键系统——这正好是线性流程的“舒适区”。
就连《人月神话》的�作者弗雷德·布鲁克斯(Fred Brooks),在领导 IBM System/360 操作系统开发时,也用了需求→设计→实现→测试的线性流程。虽然没叫瀑布模型,但他强调的文档驱动和阶段评审,后来都成了瀑布模型的核心特征。在前文中我们知道 IBM System/360 难产几年才发布的故事,但正是从它开始,软件的研发模型才具象化,也促使了经典著作《人月神话》的诞生。
致命缺陷爆发:瀑布模型的4个“坑”,逼出了后续所有模型创新
瀑布模型能稳住大型关键项目,但随着软件行业发展,它的缺陷越来越明显,几乎成了“项目翻车重灾区”:
- 错从源头起,补救全白搭:需求分析阶段的一点偏差,会像滚雪球一样贯穿整个流程,直到交付才发现,这时再改已经来不及了(
需求分析的偏差会一直向后续阶段传导); - 变更等于“推倒重来”:开发中途要改需求或设计?成本高到离谱,往往得从头返工(
难以适应需求变化); - 用户体验“盲盒”:产品原型要等到开发后期才能看到,中间过程没法验证用户感受,等发现问题已经晚了(
等待最终产品周期长); - 文档拖累效率:对文档要求极严,大量时间花在写文档上,反而耽误了开发进度(
输出大量�文档,增加时间、人力成本)。
为了填这些坑,行业开始了一波又一波的模型创新——第一个站出来的,就是带反馈的瀑布模型。
瀑布模型的初代优化:从单向流转到原型验证
带反馈的瀑布模型:打破单向却未解决核心问题
20世纪70年代末,带反馈的瀑布模型(Modified Waterfall Model)出现了。它的改进很直接:在相邻阶段之间加了“双向反馈通道”——比如设计时发现需求有问题,能回退到需求分析阶段改;编码时发现设计有缺陷,能退回设计阶段调整。
这打破了传统瀑布“只能往前走、不能回头”的绝对限制,但核心还是线性推进,文档评审要求也没减。
可惜改进有限:只能相邻阶段回退,如果测试阶段才发现需求层面的大问题,跨阶段回退还是得大量返工;而且“需求前期冻结”的核心问题没解决,还是扛不住需求变更。
就在这时,另一种更灵活的模型站了出来——原型模型(Prototype model)。
1977 年原型模型:用快速原型搞定模糊需求
1977年,巴利·玻姆(Barry Boehm,后面会多次提到的模型创新大神)系统化提出了原型模型(Prototype model)。苹果 Lisa 系统原型开发、早期交互式桌面应用、CRM系统原型验证,都用了这个模型。

图:巴利·玻姆
它的核心逻辑特别简单:先快速做一个可运行的产品原型,拿给用户看、让用户试,通过反复迭代验证需求。对于需求模糊、需要用户频繁确认的交互式软件,这简直是“救星”。
原型模型又分为抛弃型原型和演化型原型。
前者用于需求验证(比如项目开工前做一个 Demo),后者则将原型逐步迭代演化为最终产品(比如先做了个微信,包含基本聊天功能,再慢慢加上朋友圈等功能)。
原型模型的优点很突出:能快速澄清模糊需求,减少理解偏差;用户全程参与,后期需求变更风险大幅降低;早期就能验证产品方向,避免走弯路。
但它缺点也明显:
- 容易“重功能轻质量”,为了赶进度可能忽略代码规范和性能问题,导致后期维护困难
- 如果原型迭代没节制,容易导致项目范围失控,工期延误
- 不适用于高复杂度、高可靠性要求的核心系统(比如嵌入式软件、航天软件)
瀑布带原型模型:需求阶段前加 “缓冲垫”
20世纪80年代初,行业又想到了“组合拳”——把原型法和瀑布模型结合,搞出了瀑布带原型模型(Waterfall with Prototype)。
它的改进点很精准:在瀑布模型的需求分析阶段前,加了一个“原型开发环节”。先快速做个低保真或高保真原型,和客户确认清楚需求,再进入后续的线性开发流程。
这个模型早期在银行账务系统、企业库存管理系统等 MIS 项目里用得很多,完美解决了传统瀑布“需求模糊、前期确认不足”的痛点。
但局限性依然存在:如果原型阶段没覆盖所有需求问题,后续开发还是会出现和传统瀑布一样的缺陷。所以随着更优模型出现,它很快就退出了主流。
1980 年关键年:两款核心模型的双生突破
V 模型:瀑布的 “测试强化版”,成为研发基础范式
1980年是软件过程模型发展的“关键年”,这一年诞生了两个影响深远的模型,第一个就是V模型(Verification and Validation Model)。
保罗·洛克(Paul Rook)首次提出V模型的核心概念,到1990年代逐步完善成行业标准。它最典型的应用场景,是军工、航空航天等对质量要求极高的嵌入式软件项目——比如美军机载控制系统、欧洲空客航电软件。

图:空客飞机
V模型的核心创新,是把瀑布模型的“线性阶段”改成了“左侧开发+右侧测试”的对称V型结构,核心逻辑就一句话:测试活动和开发活动同步规划、提前介入。
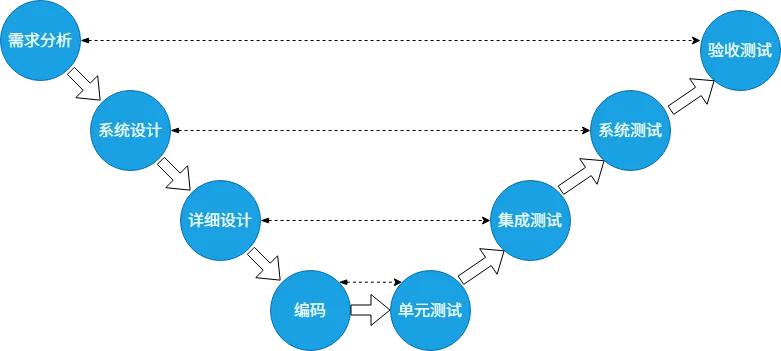
图:V模型
本质上,V模型就是瀑布模型的“测试强化版”,保留了线性推进的核心框架,重点解决了传统瀑布“测试滞后”的问题。
但它还是没跳出线性的桎梏:
- 需求变更还是要从源头回退,灵活性极差
- 测试虽然提前规划了,但实际执行还是在编码之后,没做到“边开发边测试”
- 阶段间依赖太紧,一个阶段延迟,后续所有测试环节都得拖
不过别小看V模型,它虽然不完善,却成了软件研发流程的“基础范式”——核心思想甚至融入了敏捷、DevOps 等现代研发模式,至今还在被广泛应用。
增量模型:分模块交付,突破线性局限
1980年的第二个关键模型,是巴利·玻姆提出的增量模型。
它的标志性项目包括美国国防部 DARPA 的软件项目(早期人工智能系统、军事指挥系统),后来又广泛用于大型企业级软件、ERP系统(比如SAP早期R/3系统)。
图:DARPA
增量模型的核心逻辑,是把整个软件产品按功能拆成多个“增量模块”,每个模块都走一遍“需求→设计→编码→测试→交付”的迷你瀑布流程。然后按优先级高低,先开发核心模块、先交付,再一步步开发次要模块,最后把所有模块整合起来,形成完整产品。
这个创新直接突破了传统瀑布的线性局限,带来了三个核心优势:
- 用户能提前用核心功能,降低项目整体风险
- 需求可以在后续增量模块中逐步细化,能适配部分需求变更
- 前期模块暴露的问题,能在后续模块中快速修正,减少整体返工成本
当然缺点也很明显:对模块拆分能力要求极高,如果模块间耦合度高,会频繁出现依赖冲突,协调成本飙升;前期必须明确整体架构和功能划分,架构设计错了,所有模块都受影响,后期改起来极难;如果交付节奏没规划好,用户体验会很不连贯。
所以它更适合技术成熟、风险较低的项目。
1986年,螺旋模型:把“风险控制”做到极致的王者
1986年,巴利·玻姆又在《IEEE Computer》发表论文,正式提出螺旋模型(Spiral Model)——这是一个把“风险控制”放在核心位置的模型。这次,巴利·玻姆成为了螺旋模型之父。
巴利·玻姆还有一个有趣的故事。在 TRW 公司时,玻姆团队为规范软件流程,花一年时间制定了 20 项政策和 300 页标准,核心是推广瀑布模型,还设计了类似驾照考试的 40 道 “软件流程测试题”,员工答对 35 题以上才能参与项目开发。
后来面对用户密集型决策支持系统,瀑布模型弊端凸显,团队想改用原型法却遭抵制。
员工直言 “在关键设计评审前写原型代码,既违规又不道德”。
玻姆最终推动公司转向风险驱动的流程体系,兼顾瀑布的严谨与原型的灵活,这个故事也成了软件工程中 “流程僵化与文化变革” 的经典案例。而这个事件也推动了螺旋模型的最终出世。
螺旋模型的典型应用场景,是大型、高风险、高复杂度的软件项目:比如航天飞机控制系统、核电站监控系统、早期大型操作系统 UNIX 的部分模块。

图:航天飞机
螺旋模型堪称“集大成者”,融合了三个核心优势:瀑布模型的结构化流程、增量模型的迭代交付、原型法的风险预判。
它把软件开发过程抽象成“螺旋式上升的循环”,每个循环都包含4个步骤:制定计划→风险分析→工程实现(迷你瀑布/原型开发)→评审。每一圈循环代表一个增量版本,产品越迭代越完善,最后交付完整版本。
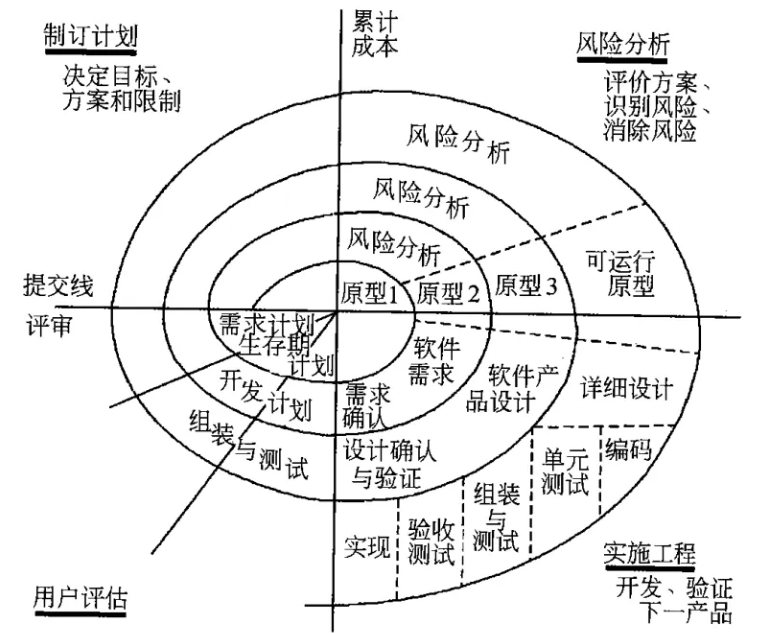
图:螺旋模型
它的核心优点全围绕风险展开:提前识别技术、需求、管理等层面的风险,避免后期爆发造成不可控损失;迭代过程中能灵活调整策略,支持需求大幅变更;结合原型法,降低需求模糊和技术实现的不确定性。
但它的门槛也极高:流程逻辑复杂,对项目管理能力要求苛刻,需要专业的风险分析团队和丰富经验,小型项目用它会成本太高、效率太低;而且循环什么时候终止没有明确标准,如果客户评估维度模糊,很容易导致项目范围无限扩大、工期延误。
快速交付为王:RAD模型,至今仍在悄悄被使用
在巴利·玻姆推动模型创新的同时,1980年代末到1990年代初,詹姆斯·马丁(James Martin)正式提出并系统化了快速应用开发模型(RAD)。
RAD 的核心目标就是“快速交付可用产品”,典型项目是需要快速上线的企业级应用、Web 应用——比如早期电商网站、CRM 系统。它能落地,全靠可视化开发工具和组件化技术(比如早��期的 VB、Delphi 开发工具)。
本质上,RAD 是增量模型、原型法和组件化开发的结合体,核心流程是“需求规划→用户设计(原型迭代)→构造系统(组件化编码/测试)→交付部署”,核心强调四点:用户全程参与、快速原型迭代、组件化复用、自动化工具支持。
它的改进特别贴合“效率需求”:
- 大幅减少文档工作量,用可运行原型替代书面文档,沟通效率翻倍;
- 组件化开发+自动化工具(代码生成器、自动化测试工具),大幅提升开发效率,缩短周期;
- 用户全程参与原型迭代,减少需求理解偏差。
缺点也很突出:过度依赖可视化工具和组件化技术,没有成熟组件可复用的话,效率会大幅下降;对团队协作和技术水平要求高,需要跨职能团队紧密配合;不适用于高复杂度、高定制化项目(比如嵌入式软件、核心算法开发),只适合业务逻辑简单的场景;原型迭代太快,容易导致代码质量差、后期维护难。
但这里有个有趣的点:即使到了2026年,RAD模型依然在被广泛使用,哪怕很多开发者自己都不知道。
比如开发企业内部OA、CRM系统,或者用若依这类框架做定制化项目——本质上就是复用现成组件快速搭建,这就是标准的RAD模型。你以为是自己的“小技巧”,其实30多年前就已经被定义好了。
V模型的升级版:W模型,把“并行测试”做到极致
20世纪90年代中后期,V模型广泛应用后,测试环节的局限性又凸显出来——虽然规划提前了,但执行还是滞后。为了解决这个问题,W模型(Double V Model)应运而生。
W模型就是“双V拼接”,是行业对V模型的集体优化,主要用在金融、电信等对质量和进度都有严格要求的项目里——比如银行核心交易系统、电信计费系统。
它的核心改进,是把V模型“开发与测试并行”的理念,从“规划层面”延伸到了“执行层面”,形成“开发V型+测试V型”的对称结构,实现“开发阶段与测试阶段全程并行”。
但它还是没跳出线性框架,需求变更的返工成本依然很高;而且全程并行对团队协作要求极高,沟通不畅的话,很容易出现测试和开发脱节,反而增加成本。
不过W模型的“全程并行测试”思想,后来也被敏捷、DevOps吸收,成了研发质量保障的底层方法。现在它虽然不是普通公司的首选,但在高质量管控场景里依然是“标准流程”——比如银行核心交易系统(毕竟“一分钟几百万上下”,容不得半点差错)、华为的基站管理软件,还有那些甲方明确要求“测试必须并行”的高要求项目。
结尾:60年进化史,本质是“对抗不确定性”的历史
从1950年代的类瀑布实践,到后来的V模型、螺旋模型、RAD模型,这60年的软件研发模型进化史,本质上是一部“对抗不确定性”的历史——对抗需求的不确定、技术的不确定、风险的不确定。
没有完美的模型,只有适合的模型:
● 瀑布模型和V模型适合需求明确的项目
● 螺旋模型适合高风险、大型项目
● 增量模型适合技术成熟、低风险项目
● 原型模型适合需求不明确,客户参与改进的项目
● RAD模型适合快速交付的组件化项目
这些开发模型,如果你要参加软考之类的考试,一定要以他们的特征来进行记忆。
这些模型的核心思想,早已融入现代研发模式里——哪怕你现在用的是敏捷、DevOps,其实也能看到瀑布、V模型、增量模型的影子。
下一篇,我们将继续深入软件架构系列,聊聊那些从这些基础模型演化而来的现代研发模型,看看它们如何解决新时代的研发难题。
关注底部微信公众号程序员爱读书,带你从源头读懂软件架构的底层逻辑~